Blog Old
PyWench is now dioivo
[link—standalone]
I decided to move the pywench tool to its own github repository. I saw this tool
improve a lot as I used it many times and each time I end up fixing something,
adding features or improving them. For this reason I want to manage it properly
in its own repository.Now
it is also installable via pip.
pip install dioivo
As I said, many things changed so some options may not be present and some others were added. In
any case it is active development so more features and improvements will come.
Fri, 22 Nov 2019 00:46Ansible Inventory
[link—standalone]
Recently I've started using ansible after a couple of years using salt stack. In general ansible feels very easy to use and very versatile. However, one of the things I miss is an easier way to handle your hosts inventory: manage groups, manage variables, etc.
For that reason I started a small program that helps me do all the inventory management using a console interface. It also integrates directly with ansible as a dynamic inventory. Here are some of the features:
Add, edit and delete hosts and groups
Add, edit and delete variables for hosts and groups
List hosts and groups
Show the hierarchy tree of group
Unique color per group, host and variable for visual identification
Use of regular expressions for bulk targeting
Importing an already existing inventory in the ansible JSON format
Direct use as a dynamic inventory with ansible (--list and --host)
Different backends with concurrency: file (for local use) and redis (for network use).
Let me show you how it looks.
You can get more information and the tool itself on github: https://github.com/diego-treitos/ansible-inventory.
As always, all sugestions are welcome so please, let me know what you think.
Fri, 22 Nov 2019 00:46[link—standalone]
Why to compress images?
One of the most important tricks to make a web page load faster is to make its components smaller. Nowadays images are one of the most common assets in web pages and also the ones that then to accumulate a big part of the web page size. This means that if you reduce the size of the images, there will be a big impact in the size of the webpage and therefore it will load noticiable faster.
I've been compressing images in websites for a while and doing benchmarks before and after the image compression. In some websites I could double the performance only with image compression.
How to compress images?
There are several very good tools to compress images but usually they are only for a single type of them (jpeg, png, etc) and usually they are used against a single file. This makes hard to apply compression to a whole website, where you would need to find all the image files and compress them depending on its type.
For this reason I created an script that finds all images, makes a backup of them and compress them with the right tool depending on type. It also has some additional features that come very handy when you are dealing with image compression every day.
The image compression script
The compression script uses mainly 4 tools and all the compression merits goes to these tools: jpegoptim (by Timo Kokkonen), pngquant (by Kornel Lesiński), pngcrush (by Andrew Chilton) and gifsicle (by Eddie Kohler). You will need to install these tools in order for the script to work and the script itself will warn you if they are not installed. In a debian/ubuntu system you can install them with this command:
sudo apt-get install jpegoptim gifsicle pngquant pngcrush
Once you have these compression tools you can start using the compression script. Lets see the options we have.
Use: ./dIb_compress_images <options> <path>
Options:
-r Revert. Replace all processed images with their
backups.
-j Compress JPEG files.
-p Compress PNG files.
-g Compress GIF files.
-L Use lossless compression.
-q Quiet mode.
-c Continue an already started compression. This will
convert only not already backuped files.
-t <percentage> Only use the converted file if the compression
saves more than size. The files not
below will appear as 0% in output.
NOTE: If none of -j, -p or -g are specified all of them (-j -p -g)
will be used.
So yo can choose which types of images you want to compress (by default all of them) in a given path. The script will find those image types recursively inside that path and compress them.
You can compress them using lossy compression (default and recommended) or lossess (with -L flag). Usually using lossy compression makes no visual differences for the naked eye between the non-compressed and compressed version of a image. Lossy compression gives a much compressed version of the image so it is recommended.
For each image, the script will make a backup and this backup will not be ever overwritten so the backup will always be the original image. In case you want to revert the changes because you found some visual differences or whatever, you can use the -r flag over the same path, which will cause all the image backups to be restored.
By default, each time you execute the script on a given path, it will recompress all the images despite if they were already compressed or not. If you want to skip the already compressed images, you can use the -c flag. If you use it together with the quiet mode flag (-q) you can add the script to a cron task to periodically compress the images of your site.
You can also specify a percentage threshold so you can only keep the compressed version of an image if it saves at least that percentage in its used space with the -t parameter.
Here is an example output of the most basic execution. It is compressing images from a real website, altough I changed the image names in the script output for security reasons.
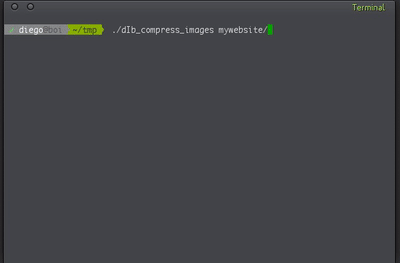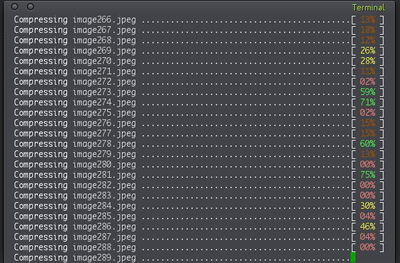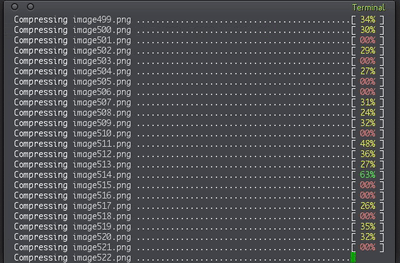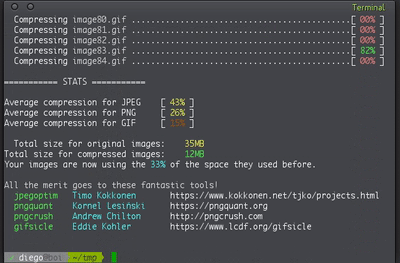
In this case, the images used 35MB but after compression they only use 12MB, that is a 33% of their original size!
Again, these compression rates are due to the fantastic tools the script uses. What I did was to gather information from many tests to find the best options for these tools to get the best balance between size and quality (and also compression time).
As always, let me know your thoughts and sugestions to improve it are more than welcome!
The script is available here: https://github.com/diego-treitos/dgtool/blob/master/compress_images/dIb_compress_images
Fri, 22 Nov 2019 00:46
PyWench: Huge improvements
[link—standalone]
I've recently been paying some attention to this tool. I've discovered some bugs and some great room for improvements.
Basically I found that the rps metric was not very precise and also that the performance of the application was not very good.
Regarding the requests per second issue, I changed the way they are calculated and now I can grant that the results are quite accurate (compared to what I see in the log files of the benchmarked server).
I've also found that the performance was quite bad, mainly because of the python threading system and the python GIL. So I decided to migrate the tool to python multiprocessing and the performance improvements have been huge: almost 3 times faster.
As I was already changing things I also changed the plotting library from gnuplot to matplotlib as gnuplot wasn't very stable. This also implies that the plot cannot be viewed live anymore and the "-l" option will now allow you to play with the plot once the benchmark is done. Also, now the tool should work properly in systems with out xserver.
Please, be aware that you need a big server (several cores, big bandwidth, etc) in order to benchmark a website properly instead of end up benchmarking the tool itself or your bandwidth connection. I will still work in this tool in the future and one of the things I would like to do is to make it distributed so it can run a benchmark from different servers and then gather all the results in a central node. This would help to eliminate bottlenecks in the client side of the benchmark.
Please, if you use the tool report any bug you see and of course let me know if you see how to improve the tool. All comments are welcome :).
You can already find this new version at: https://github.com/diego-XA/dgtool/tree/master/pywench
Fri, 22 Nov 2019 00:46[link—standalone]
Well, it's been a while since the last publication but here I am again with a new tool I wrote. I sometimes have to take a look on how web sites are performing so I need a tool to see if the configuration changes I make are taking effect and measure the performance differences. There are some tools like apache benchmark that can be used to benchmark web performance but they only accept a single URL to test, which is far away from a normal usage of a site.
So I wrote a tool that uses the access log file from apache or nginx and rips the URL paths to test so we can measure better how a "normal" usage of the site will behave with this or that configuration. It also reports some stats and plots a graph with the timings. To have an idea of what this tool can do, lets see its options.
root@dgtool:~# pywench --help
Usage: pywench [options] -s SERVER -u URLS_FILE -c CONCURRENCY -n NUMBER_OF_REQUESTS
Options:
-h, --help show this help message and exit
-s SERVER, --server=SERVER
Server to benchmark. It must include the protocol and
lack of trailing slash. For example:
https://example.com
-u URLS_FILE, --urls=URLS_FILE
File with url's to test. This file must be directly an
access.log file from nginx or apache.'
-c CONCURRENCY, --concurrency=CONCURRENCY
Number of concurrent requests
-n TOTAL_REQUESTS, --number-of-requests=TOTAL_REQUESTS
Number of requests to send to the host.
-m MODE, --mode=MODE Mode can be 'random' or 'sequence'. It defines how the
urls will be chosen from the url's file.
-R REPLACE_PARAMETER, --replace-parameter=REPLACE_PARAMETER
Replace parameter on the URLs that have such
parameter: p.e.: 'user=hackme' will set the parameter
'user' to 'hackme' on all url that have the 'user'
parameter. Can be called several times to make
multiple replacements.
-A AUTH_RULE, --auth=AUTH_RULE
Adds rule for form authentication with cookies.
Syntax:
'METHOD::URL[::param1=value1[::param2=value2]...]'.
For example: POST::http://example.com/login.py::user=r
oot::pass=hackme
-H HTTP_VERSION, --http-version=HTTP_VERSION
Defines which protocol version to use. Use '11' for
HTTP 1.1 and '10' for HTTP 1.0
-l, --live If you enable this flag, you'll be able to see the
realtime plot of the benchmark
Most of the parameters like the SERVER, CONCURRENCY, TOTAL_REQUESTS are probably well known or self-explanatory for you, but you can also see other parameters that are not so common, so let me explain them:
URLS_FILE: This is the access log file from nginx or apache server. So if you want to test your server, you will only have to download the access log and use it as the input file. Please note that it takes the 7th column of the log file as the URL path.
MODE: The URLs can be extracted from URLS_FILE randomly or in the order they appear. You can choose it with the MODE parameter.
REPLACE_PARAMETER: Sometimes you need to pass an specific parameter so the server will answer as if you were a normal user (maybe a session string, a user name, etc). If you use this option, any URL from URLS_FILE will be checked for the parameter you want to replace and if the parameter exists, its value will be replaced with the value you specify.
AUTH_RULE: Sometimes you need to authenticate to a server before starting the benchmark to ensure that you are treated as a normal user. With this option you can choose how to authenticate, pass the authentication options and, before the benchmark starts, PyWench will login into the website and save the cookie and this auth cookie will be used for all the requests.
HTTP_VERSION: You can use HTTP 1.0 or HTTP 1.1 for the benchmarks.
--live: This will show you a live plot of how well the server is doing serving the PyWench requests during the benchmark.
Well, lets see how it works with an example! In this example we will test our favourite server: example.com. It will be a basic usage case.
To start the benchmark we will need two things: the server URL (protocol and domain name) and the access.log file. In this example we will use https://www.example.com as server URL (to point out that it also works with HTTPS). We will start with 500 requests and a concurrency of 50.
root@dgtool:~# /pywench -s "https://www.example.com" -u access_log -c 50 -n 500
Requests: 500 Concurrency: 50
[==================================================]
Stopping... DONE
Compiling stats... DONE
Stats (seconds)
min avg max
ttfb 0.15178 7.46277 103.63504
ttlb 0.15299 7.58585 103.63520
Requests per second: 6.591
URL min ttfb: (0.15178) /gallery/now/thumbs/thumbs_img_0401-1024x690.jpg
URL max ttfb: (89.01898) /gallery/then/02_03_2011_0007-2.jpg
URL min ttlb: (0.15336) /gallery/now/thumbs/thumbs_img_0401-1024x690.jpg
URL max ttlb: (90.55633) /gallery/then/02_03_2011_0007-2.jpg
NOTE: These stats are based on the average time (ttfb or ttlb) for each url.
Protocol stats:
HTTP 200: 499 requests (99.80%)
HTTP 404: 1 requests ( 0.20%)
Press ENTER to save data and exit.
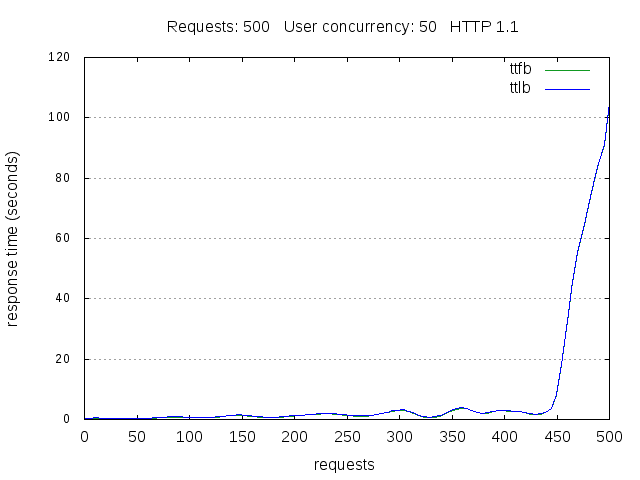
Well, as you can see, we already have some stats in the output: there are some statistics regarding the timings for ttfb (time to first byte), ttlb (time to last byte) , the fastest and slowest URL and some error code stats.
There also were created 3 files in the working directory:
www.example.com_r500_c50_http11.log: Log file with all the gathered data. It is like a CSV with the start time, url, ttfb and ttlb of each request.
www.example.com_r500_c50_http11.stat: It contains a python dictionary with the stats reported in the command line.
www.example.com_r500_c50_http11.png: A plot of the benchmark. This plot is also what you see if you use the --live option. See the following image.
REQUIREMENTS
So, if you are in a Debian/Ubuntu system: apt-get install python-urllib3 python-gnuplot gnuplot-x11
UPDATE: Check the last post with the latest modifications: https://www.treitos.com/blog/old/pywench-huge-improvements.html
You can access this tool clicking this URL: https://github.com/diego-XA/dgtool/tree/master/pywench
As always, comments are welcome so if you have any question, found a bug or have a suggestiong, please let me know.
Fri, 22 Nov 2019 00:45
Autoremove unreachable node from balanced DNS
[link—standalone]
When you are offering a high availability service, you often balance users among nodes using DNS. The problem with DNS is the propagation time so, in case of a node failure, a quick response is very important. This is the reason why I developed a tiny script that checks the status of the balanced nodes for the bind9 DNS server.
The script will need a little modification on your bind9 zone files. This is the syntax:
[..]
ftp.example.com 3600 IN A 258.421.3.125
;; BALANCED_AUTOCHECK::80
balancer-www 120 IN A 258.421.3.182
balancer-www 120 IN A 258.421.3.183
balancer-http 3600 IN CNAME balancer-www.example.com.
[..]
Here we have the subdomain balancer-www balanced between two hosts with IP's 258.421.3.182, 258.421.3.183. At the top of these A records we have the "code" that we have to add for the script to know how to proceed. The sintax is simple: ;; BALANCED_AUTOCHECK::<service_port>. The BALANCED_AUTOCHECK part is only a matching pattern and the <service_port> is the port of the service to check. In the above example, we are checking a balancer for an http service, so we are using the port 80.
NOTE: For your interest, the rule matches the regular expression: ;;\s*BALANCED_AUTOCHECK::\d+$
Please, have in mind that no protocol check is made (i.e.: HTTP 400 errors, etc) but only a plain socket connection. If the socket connection fails, the IP is marked as down by commenting the A record it and if a recover is detected, the A record is uncommented.
Here is the help output of the script:
Usage: bind9_check_balancer [options] [dns_files]
Options:
-h, --help show this help message and exit
-c COMMAND, --command=COMMAND
Command to be executed if changes are made.
(example:'service bind9 restart')
-t TIMEOUT, --timeout=TIMEOUT
Socket timeout for unreachable hosts in seconds.
Default: 5
I think it explains quite well how it works but, just in case, here are some examples:
# Check test.net.hosts and test.com.hosts. If a change is made
# (down/recover detected), exec the command: /etc/init.d/bind9 reload
bind9_check_balancer -c '/etc/init.d/bind9 reload' /etc/named/test.net.hosts /etc/bind/test.com.hosts
# Check all files in /etc/named/zones directory and set a timeout
# of 1 second for connection checks. Also exec: service bind9 reload
bind9_check_balancer -c 'service bind9 reload' /etc/named/zones/*
This script is intempted to be executed as a cron job each minute or each 5 minutes (or each time you want). You can get the script form dgtool github repository at: https://github.com/diego-XA/dgtool/blob/master/ha/bind9_check_balancer
Fri, 22 Nov 2019 00:45NGINX as sticky balancer for HA using cookies
[link—standalone]
I recently needed to find a solution to implement several http load balancers that balance among several backend servers so each balancer can proxyfy any of the backend servers. The abstract architecture of the deploy is represented in this image.
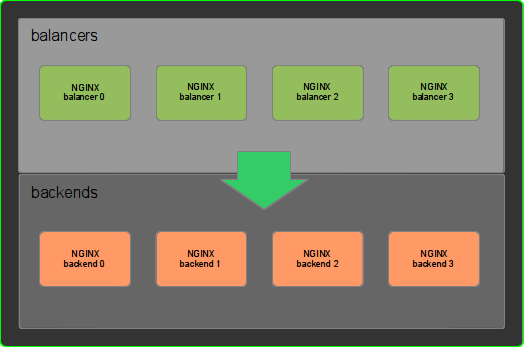
Yes, the backends have an NGINX, I'll explain that later...
Of course one of the requirements was that the session had to be kept but there was a problem: the backend server did not synchronized the session among themselves. This situation directly required the balancers to send each user to the same backend server each time the user makes a request. This way, as the one user is using only one backend, there won't be any problem with the session persistence.
I know that the Upstream Module from NGINX provide the above feature through the ip_hash parameter as, if you have in all the balancer servers the same list of backends in the same order, the IP for a user will always match the same backend server. You can check this taking a look at the module source code at
nginx-X.X.XX/src/http/modules/ngx_http_upstream_ip_hash_module.c.
However, using this module has several cons:
No support for IPv6. In fact, all request from an IPv6 will be redirected to the first backend server (as I understood from the source code). NOTE: IPv6 addresses are supported starting from versions 1.3.2 and 1.2.2. The version included in last ubuntu (12.10) is 1.1.19 and it is the version I was testing so it lacks of ipv6 support.
Colissions as it only uses the 3 first numbers of the IP for the hash. That means that all the ips of the same C-class network range will go to the same backend server.
All users behind a NAT will access to the same backend server.
If you add new backends, all the hashes will change and sessions will be lost.
Because of these problems there are some situations where the balacers will not be fair at all, overloading some nodes while others are idle. For this reason I wondered if it could be possible to balance among servers using other solution than ip_hash.
I found the project nginx-sticky-module which uses cookies for balance among backneds, but it is not integrated into nginx so I had to recompile it which I don't really like for production environments as I prefer to use official packages from the GNU/Linux distribution. So I wondered... would be NGINX so versatile that would let me implement something like this module only using configuration parameters? Guess the answer! There exist a way!
So, now that we are in context, let's start with a little test. Our objective in this example is to use nginx to balance between two backend nodes using cookies. The solution we will implement will work the way it is represented in the following diagram.
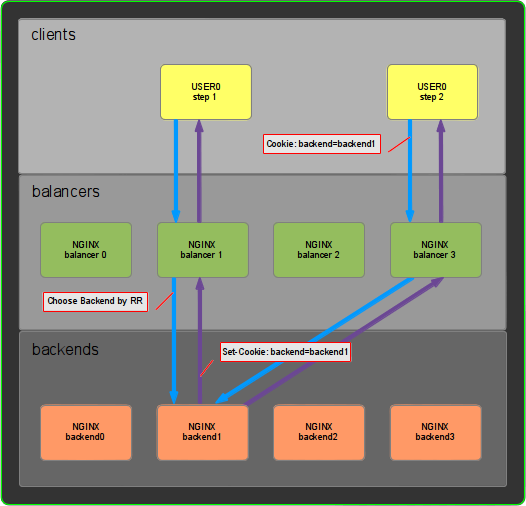
In the diagram you can see that the user USER0 when accessing to our application service is directed to balancer1 probably through a DNS round robin resolution. In step 1 the user accesses for the first time to the service so the balancer1 will choose one backend by round robin and, in this example, backend1 was chosen (for the luck of our draftsman). This backend will set the cookie backend=backend1 so the client have "registered" in the backend.
At step 2 the user will access the platform for the second time. This time, the DNS round robin will send our user to the balancer balancer3 and, thanks to the cookie named backend, the balancer will be able to know which backned should attend the request: backend1.
Now that we know how it works, how do we make it work with NGINX ?
Well, lets talk first about how the cookie is set in the backend server. If you can change some code on the web application you can force the application to set the cookie for you. If not, you can proxify the application with NGINX in the same server and you could even use that NGINX to implement the cache of the platform. I will choose to proxyfy the backend application with NGINX as it is a generic solution to our problem.
So a very simple configuration of the NGINX in the backend server backend1 would look like this:
server {
listen 80;
location / {
add_header Set-Cookie backend=backend1;
proxy_pass http://localhost:8000/;
proxy_set_header X-Real-IP $remote_addr;
}
}
Each backend server will have to have an specific configuration with its backend identifier. I recommend you for testing to set up two backends like this one with ids backend1 and backend2. Of course in production environments we could use md5 hashes or uuids to avoid predictable identifiers.
We can now configure a balancer to balance between these two backends. The balancer configuration would look like this:
upstream rrbackend {
server 192.168.122.201;
server 192.168.122.202;
}
map $cookie_backend $sticky_backend {
default bad_gateway;
backend1 192.168.122.201;
backend2 192.168.122.202;
}
server {
listen 80;
location / {
error_page 502 @rrfallback;
proxy_pass http://$sticky_backend$uri;
}
location @rrfallback {
proxy_pass http://rrbackend;
}
}
The good part is that the configuration will be the same for all balancers if you have more than one. But lets explain how this configuration works.
In first place we declare the backends for the round robin access.
Then we map the cookie backend variable to the $sticky_backend NGINX variable. If $cookie_backend is backend1, then $sticky_backend value will be 192.168.122.201 and so on. If no match is found, the default value bad_gateway will be used. This part will be used to choos the sticky backend.
The next thing is to declare the server part, with its port (server_name and whatever) and its locations. Note that we have a @rrfallback location that resolves to a backend using round robin. When a user access the location /, two things can happen:
The user accesses for the first time so no backend cookie is provided and $sticky_backend NGINX variable will have the value bad_gateway. In this case, the proxy_pass will try to access a server called bad_gateway which will return an error 502 (Bad Gateway) and, as declared in the line above the proxy_pass, this error will fallback to @rrfallback so a backend will be choosed by round robin.
The users passes the backend cookie with a valid value so the $sticky_backend NGINX variable will have a valid IP from the map and redirected to the backend indicated in the cookie through the proxy_pass.
The same than 2. but the backend is down. In this case, the proxy_pass will return a 502 error and the process will start from 1: new backend by round-robin.
And this is all! You can test it both with a browser to check that you'll stay on the same server or make requests with curl/wget without sending the cookie to check the initial round-robin.
Fri, 22 Nov 2019 00:45Watch realtime HTTP requests per second
[link—standalone]
I've recently wanted to know how many requests per second where I having on a server. The server is using nginx as server and this is the way I found:
watch -n 1 'a="$(date +%d/%b/%Y:%H:%M:$(($(date +%S)-1)))";grep -c "$a" access.log'
I decrease the seconds in 1 unit as the current second could not be finished when the check is done (yes, it will fail on second 0 but... we have 59 seconds more!).
You'll have to change the path to your access log file. You'll probably have to change the format of the date for other formats of access.log. Anybody knows a better way?
Fri, 22 Nov 2019 00:45ErlyVideo connector
[link—standalone]
I've recenctly worked with ErlyVideo servers. They allow you to manage RTMP streams so you can serve them in a web page using a flash player. They work pretty well but they have a big fail: then cannot be concatenated. What do I mean by concatenate? I mean that you cannot use an ErlyVideo server as source of other ErlyVideo. At least, in my tests, the result was a corrupted video output.
As there is a big lack of documentation regarding ErlyVideo configuration and deploy arquitecture, I decided to code a little application that would receive the rtmp streams from an ErlyVideo server and send them to other one. Using ffmpeg you can accomplish this job as it supports rtmp , but you need an application to manage all the ffmpegs and the streams and, once you are working on, it's a good idea to code some user interface. And this is the result: erlyconnect. It is a very simple application but it has been very useful.
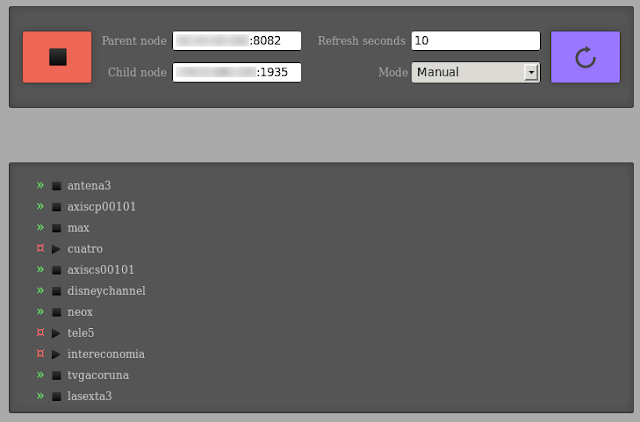
As always, you can download it from the github repository at: https://github.com/diego-XA/dgtool/tree/master/erlyconnect/trunk
There is a README file to see how it works. Please, let me know if you find some bug or just have some doubts about how it works.
Fri, 22 Nov 2019 00:45Python subprocess daemon manager - Pylot
[link—standalone]
One of the things I usually need is to execute subprocess daemons from python scripts to run task or even to offer some service that I need to be controlled by python code.
Executing subprocesses from python is quite easy with the Popen function from the subprocess module. You can exec subprocesses using an "exec" call, using a shell and you have a lot of parameters. This is quite cool, but sometimes you need to manage many daemons and you need them to be killed if the parent process dies and relaunched if they die. And there is other problem, if you send a SIGKILL signal to the parent process, the child processes will keep running and uncontrolled by any other program.
That is the reason I've implemented a module called Pylot. This module has two clases, Pylot and PylotManager. The first one is a thread that will execute the subprocess you want and other subprocess that acts as a watcher: if the main process dies, all your subprocesses will be killed by their watchers. Why to use watchers instead of capturing the SIGKILL signal??? Well, that is because... you can't capture the SIGKILL signal!
The PylotManager class will be used as an interface to handle the Pylots. You will be able to create, delete, check status and access the Pylots from PylotManager. PylotManager will check for the status of the Pylots and will relaunch them if they die, so it keeps all the daemons up and running.
Let's see a little example of how it works:
# Import PylotManager
from Pylot import PylotManager
# Create a new PylotManager and start it
pm = PylotManager()
pm.start()
# Once started, we can add a pylot for our daemon: htop
# NOTE: we set flush_output to False so we can later access
# stderr and stdout. By default, flush_output is True so
# you do not have to read the process output and you save
# memory.
pm.addPylot('myfirstPylot','htop', flush_output=False)
# Now we access to our pylot
p = pm.getPylots()['myfirstPylot']
print p.pid
print p.stderr.read()
print p.stdout.read()
# Lets stop our pylot
pm.stopPylot('myfirstPylot')
# Now lets stop PylotManager. All remaining pylots will also
# be stopped
pm.stop()
As easy as it looks like. All the code is commented so you can see all the functions and parameters with the python help() command.
You can get the code from https://github.com/diego-XA/dgtool/tree/master/pylot and you are free to use it and change it. If you find some bug or have a feature request, just comment.
Bye for now!
Fri, 22 Nov 2019 00:45Power On/Off Scheduling
[link—standalone]
Some time ago, I applied for a job where I had to implement a tool to schedule power on and power off on a computer.
The target was to have a file where to define a weekly schedule. There also should be a software to parse that file and act in consequence. It was also needed to add exceptions on certain days, specified by month and month day, where the schedule has to be different from the matching day of week. So the file should look something like this:
[week]
Monday = 8.30-20.00
Tuesday = 8.30-13.15
Wednesday = 8.30-
Thursday = -20.00
Friday = 8.30-19.00
Saturday =
Sunday = 8.30-20.00
[exceptions]
Nov_25 = 8.30-22.00
Sadly, the company that was hiring me tricked me with the price so we never achieved an agreement (or at least that's what I deduced from having no answer to my mails). However, as they needed it urgently, I was implementing the software during the negotiations so that I had finished my job when thy stopped answering me. So, as I thought it is an interesting software and there are many people that unknown how to do schedule a power on, I decided to post it in my blog.
Let's get to the point. This tool was coded in python and it has 3 pieces:
powerscheduler.py implements the main program that uses the rest of classes.
schedulereader.py implements the configuration file parsing.
necromancer.py implements the set up of power on and power off schedules.
As you can see, all the interesting magic will be in necromancer.py file, so let's see how we can schedule the killing of our computer and then get it back from the Avernus.
First we'll see the easy thing: how to schedule the shutdown. Of course the easiest way of doing this is to create a cron task. So when we schedule a power off, necromancer.py will create a file in /etc/cron.d/necromancer_poweroff which will call shutdown and then it will erase itself.
How do we schedule the power on? Using the rtc timer of course. To check if your computer supports rtc, you just have to check if /proc/driver/rtc file exists. The rtc clock is the clock we configure in our BIOS, is the hardware clock, so the first thing we have to check is whether the rtc clock and the system clock have the same date and time (our computer could be using NTP so the hardware clock could be completely different from system time). Also is important to care about the time zone so that hwclock usually is set to UTC and the system time is calculated using it's time zone.
To solve this problem, the firs thing that necromancer.py does is to set the hardware clock to UTC based on the system time. This way we can ensure that if we work in UTC, the time will be always the same in system and rtc.
Now we can schedule a power on date. This can be done by writing the date into the file /sys/class/rtc/rtc0/wakealarm. That date must be in UTC time. We can test with these commands:
# echo 0 > /sys/class/rtc/rtc0/wakealarm
# date -d "1:25:00 Dec 22, 2012" +%s >/sys/class/rtc/rtc0/wakealarm
# cat /proc/driver/rtc
rtc_time : 12:56:37
rtc_date : 2011-12-09
alrm_time : 00:25:00
alrm_date : 2012-12-22
alarm_IRQ : yes
alrm_pending : no
update IRQ enabled : no
periodic IRQ enabled : no
periodic IRQ frequency : 1024
max user IRQ frequency : 64
24hr : yes
periodic_IRQ : no
update_IRQ : no
HPET_emulated : yes
BCD : yes
DST_enable : no
periodic_freq : 1024
batt_status : okay
The first line resets the rtc wake alarm. We set the wake alarm in the second line (note the -u parameter to use UTC). In the third line, we see the lines alrm_time and alrm_date. As you can see, the alarm is established for the date we specified. I'm in UTC+1 so the time is one hour less to be in UTC.
All this is done in necromancer.py. But, how the software works altogether? Well, It's simple, once you have changed the schedule in the configuration file stored in /etc/power_scheduler.cfg by default, the powerscheduler.py tool has to be called. This can be done calling the script from cron each five minutes or so but I recomment to use icron as the best solution. I'll talk about icron in other post some day.
Well, thats all for now. All the files used here are stored in https://github.com/diego-XA/dgtool/tree/master/powerscheduler. Feel free to use the tool and modify it.
Fri, 22 Nov 2019 00:45SSL encryption in python bottle
[link—standalone]
Bottle is a really powerful tool to develop light weight applications quickly. Recently I was programming little web service with bottle. Something easy. The point is that my service required SSL encryption to have a little more security and, after some googling, I couldn't find any quick&easy howto. However I looked into the bottle code an realised that there would be a good way of doing such thing... and here it is.
Well, the first thing is to know that bottle can use several web servers as backends. So the way of bottle supporting SSL is that one of those servers support it. By default, it uses the wsgiref server that does not support SSL.
On the other hand, one of the biggest benefits of bottle is that is very lightweight: the python-bottle debian package uses only 176KB so, if I have to use other web server than default as backend, I don't want to be a heavy one. Finally I decided to use cherrypy, as it seemed to be supported... but not the way I thought.
There are two debian packages that provide cherrypy: python-cherrypy and python-cherrypy3. The first one uses 920KB of disk and the second one 15MB. Only the second is supported by bottle by default. Wow! I have an application that uses about 200KB of disk (bottle included) and should I use 15MB of disk to give it SSL support? Of course not!
Lets see some code. This is a sample of my application.
#!/usr/bin/env python
#-*- coding:utf-8 -*-
from bottle import Bottle, run, request
app = Bottle()
@app.post('/login')
def login():
name = request.forms.get('name')
password = request.forms.get('password')
if (name, password) == ('root','hackme'):
return "<p>Your login was correct</p>"
else:
return "<p>Login failed</p>"
run(app, host='localhost', port='8080')
Yes, I'm kidding, it's not a sample of my application but a copy&paste of bottle tutorial... O:).
Well, lets exec this server and test it:
Terminal 1: Server running
Terminal 2: Testing server with curl
Terminal 3: Tcpdump watching
Terminal 1:
$ ./app1.py
Bottle server starting up (using WSGIRefServer())...
Listening on http://localhost:8080/
Use Ctrl-C to quit.
localhost - - [06/Dec/2011 22:44:12] "POST /login HTTP/1.1" 200 19
Terminal 2:
$ curl -d 'name=root&password=hackme' http://localhost:8080/login
<p>Your login was correct</p>
Terminal 3:
# tcpdump -i lo dst port 8080 -XXX
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on lo, link-type EN10MB (Ethernet), capture size 65535 bytes
22:44:12.469205 IP localhost.38409 > localhost.http-alt: Flags [S], seq 887660788, win 32792, options [mss 16396,sackOK,TS val 735295 ecr 0,nop,wscale 4], length 0
0x0000: 0000 0000 0000 0000 0000 0000 0800 4500 ..............E.
0x0010: 003c 98cb 4000 4006 a3ee 7f00 0001 7f00 .<..@.@.........
0x0020: 0001 9609 1f90 34e8 a0f4 0000 0000 a002 ......4.........
0x0030: 8018 fe30 0000 0204 400c 0402 080a 000b ...0....@.......
0x0040: 383f 0000 0000 0103 0304 8?........
22:44:12.469246 IP localhost.38409 > localhost.http-alt: Flags [.], ack 1094336116, win 2050, options [nop,nop,TS val 735295 ecr 735295], length 0
0x0000: 0000 0000 0000 0000 0000 0000 0800 4500 ..............E.
0x0010: 0034 98cc 4000 4006 a3f5 7f00 0001 7f00 .4..@.@.........
0x0020: 0001 9609 1f90 34e8 a0f5 413a 3e74 8010 ......4...A:>t..
0x0030: 0802 fe28 0000 0101 080a 000b 383f 000b ...(........8?..
0x0040: 383f 8?
22:44:12.469377 IP localhost.38409 > localhost.http-alt: Flags [P.], seq 0:265, ack 1, win 2050, options [nop,nop,TS val 735295 ecr 735295], length 265
0x0000: 0000 0000 0000 0000 0000 0000 0800 4500 ..............E.
0x0010: 013d 98cd 4000 4006 a2eb 7f00 0001 7f00 .=..@.@.........
0x0020: 0001 9609 1f90 34e8 a0f5 413a 3e74 8018 ......4...A:>t..
0x0030: 0802 ff31 0000 0101 080a 000b 383f 000b ...1........8?..
0x0040: 383f 504f 5354 202f 6c6f 6769 6e20 4854 8?POST./login.HT
0x0050: 5450 2f31 2e31 0d0a 5573 6572 2d41 6765 TP/1.1..User-Age
0x0060: 6e74 3a20 6375 726c 2f37 2e32 312e 3620 nt:.curl/7.21.6.
0x0070: 2869 3638 362d 7063 2d6c 696e 7578 2d67 (i686-pc-linux-g
0x0080: 6e75 2920 6c69 6263 7572 6c2f 372e 3231 nu).libcurl/7.21
0x0090: 2e36 204f 7065 6e53 534c 2f31 2e30 2e30 .6.OpenSSL/1.0.0
0x00a0: 6520 7a6c 6962 2f31 2e32 2e33 2e34 206c e.zlib/1.2.3.4.l
0x00b0: 6962 6964 6e2f 312e 3232 206c 6962 7274 ibidn/1.22.librt
0x00c0: 6d70 2f32 2e33 0d0a 486f 7374 3a20 6c6f mp/2.3..Host:.lo
0x00d0: 6361 6c68 6f73 743a 3830 3830 0d0a 4163 calhost:8080..Ac
0x00e0: 6365 7074 3a20 2a2f 2a0d 0a43 6f6e 7465 cept:.*/*..Conte
0x00f0: 6e74 2d4c 656e 6774 683a 2032 350d 0a43 nt-Length:.25..C
0x0100: 6f6e 7465 6e74 2d54 7970 653a 2061 7070 ontent-Type:.app
0x0110: 6c69 6361 7469 6f6e 2f78 2d77 7777 2d66 lication/x-www-f
0x0120: 6f72 6d2d 7572 6c65 6e63 6f64 6564 0d0a orm-urlencoded..
0x0130: 0d0a 6e61 6d65 3d72 6f6f 7426 7061 7373 ..name=root&pass
0x0140: 776f 7264 3d68 6163 6b6d 65 word=hackme
Well, there it is. The traffic is not encrypted.
What we are going to do to include SSL support is to add a new server class that inherits from bottle.ServerAdapter and that will support SSL through cherrypy._cpwsgiserver3 included in python-cherrypy debian package instead of using cherrypy.wsgiserver provided by python-cherrypy3 debian package which is the supported one by bottle.
First of all, we will need to generate the .pem file. You can use this command:
openssl req -new -x509 -keyout server.pem -out server.pem -days 365 -nodes
I saved my server.pem file in /var/tmp/server.pem for this sample. Lets see the new code of our sample.
#!/usr/bin/env python
#-*- coding:utf-8 -*-
from bottle import Bottle, run, request, server_names, ServerAdapter
# Declaration of new class that inherits from ServerAdapter
# It's almost equal to the supported cherrypy class CherryPyServer
class MySSLCherryPy(ServerAdapter):
def run(self, handler):
from cherrypy import _cpwsgiserver3
server = _cpwsgiserver3.CherryPyWSGIServer((self.host, self.port), handler)
# If cert variable is has a valid path, SSL will be used
# You can set it to None to disable SSL
cert = '/var/tmp/server.pem' # certificate path
server.ssl_certificate = cert
server.ssl_private_key = cert
try:
server.start()
finally:
server.stop()
# Add our new MySSLCherryPy class to the supported servers
# under the key 'mysslcherrypy'
server_names['mysslcherrypy'] = MySSLCherryPy
app = Bottle()
@app.post('/login')
def login():
name = request.forms.get('name')
password = request.forms.get('password')
if (name, password) == ('root','hackme'):
return "<p>Your login was correct</p>"
else:
return "<p>Login failed</p>"
# Add an additional parameter server='mysslcherrypy' so bottle
# will use our class
run(app, host='localhost', port='8080', server='mysslcherrypy')
As you can see, there is not a lot of code but, does it work?
As before, Terminal 1 is executing our application.
Terminal 2:
$ curl -d 'name=root&password=hackme' -k https://localhost:8080/login
<p>Your login was correct</p>
Note that we use -k to accept unverified certificates and, of course, https protocol.
Terminal 3:
# tcpdump -i lo dst port 8080 -XXX
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on lo, link-type EN10MB (Ethernet), capture size 65535 bytes
23:41:57.494848 IP localhost.38570 > localhost.http-alt: Flags [S], seq 3160714269, win 32792, options [mss 16396,sackOK,TS val 1454551 ecr 0,nop,wscale 4], length 0
0x0000: 0000 0000 0000 0000 0000 0000 0800 4500 ..............E.
0x0010: 003c 9dca 4000 4006 9eef 7f00 0001 7f00 .<..@.@.........
0x0020: 0001 96aa 1f90 bc64 ac1d 0000 0000 a002 .......d........
0x0030: 8018 fe30 0000 0204 400c 0402 080a 0016 ...0....@.......
0x0040: 31d7 0000 0000 0103 0304 1.........
23:41:57.494891 IP localhost.38570 > localhost.http-alt: Flags [.], ack 8931266, win 2050, options [nop,nop,TS val 1454551 ecr 1454551], length 0
0x0000: 0000 0000 0000 0000 0000 0000 0800 4500 ..............E.
0x0010: 0034 9dcb 4000 4006 9ef6 7f00 0001 7f00 .4..@.@.........
0x0020: 0001 96aa 1f90 bc64 ac1e 0088 47c2 8010 .......d....G...
0x0030: 0802 fe28 0000 0101 080a 0016 31d7 0016 ...(........1...
0x0040: 31d7 1.
23:41:57.497047 IP localhost.38570 > localhost.http-alt: Flags [P.], seq 0:223, ack 1, win 2050, options [nop,nop,TS val 1454552 ecr 1454551], length 223
0x0000: 0000 0000 0000 0000 0000 0000 0800 4500 ..............E.
0x0010: 0113 9dcc 4000 4006 9e16 7f00 0001 7f00 ....@.@.........
0x0020: 0001 96aa 1f90 bc64 ac1e 0088 47c2 8018 .......d....G...
0x0030: 0802 ff07 0000 0101 080a 0016 31d8 0016 ............1...
0x0040: 31d7 1603 0100 da01 0000 d603 014e de9a 1............N..
0x0050: 35a9 ac95 ef29 5caf 4f47 a873 62fc 9cea 5....)\.OG.sb...
0x0060: 9bda cacd 60aa ffa7 ca56 a00e 0800 005a ....`....V.....Z
0x0070: c014 c00a 0039 0038 0088 0087 c00f c005 .....9.8........
0x0080: 0035 0084 c012 c008 0016 0013 c00d c003 .5..............
0x0090: 000a c013 c009 0033 0032 009a 0099 0045 .......3.2.....E
0x00a0: 0044 c00e c004 002f 0096 0041 c011 c007 .D...../...A....
0x00b0: c00c c002 0005 0004 0015 0012 0009 0014 ................
0x00c0: 0011 0008 0006 0003 00ff 0201 0000 5200 ..............R.
0x00d0: 0000 0e00 0c00 0009 6c6f 6361 6c68 6f73 ........localhos
0x00e0: 7400 0b00 0403 0001 0200 0a00 3400 3200 t...........4.2.
0x00f0: 0100 0200 0300 0400 0500 0600 0700 0800 ................
0x0100: 0900 0a00 0b00 0c00 0d00 0e00 0f00 1000 ................
0x0110: 1100 1200 1300 1400 1500 1600 1700 1800 ................
0x0120: 19 .
23:41:57.506522 IP localhost.38570 > localhost.http-alt: Flags [.], ack 801, win 2150, options [nop,nop,TS val 1454554 ecr 1454554], length 0
0x0000: 0000 0000 0000 0000 0000 0000 0800 4500 ..............E.
0x0010: 0034 9dcd 4000 4006 9ef4 7f00 0001 7f00 .4..@.@.........
0x0020: 0001 96aa 1f90 bc64 acfd 0088 4ae2 8010 .......d....J...
0x0030: 0866 fe28 0000 0101 080a 0016 31da 0016 .f.(........1...
0x0040: 31da 1.
23:41:57.512658 IP localhost.38570 > localhost.http-alt: Flags [P.], seq 223:421, ack 801, win 2150, options [nop,nop,TS val 1454555 ecr 1454554], length 198
0x0000: 0000 0000 0000 0000 0000 0000 0800 4500 ..............E.
0x0010: 00fa 9dce 4000 4006 9e2d 7f00 0001 7f00 ....@.@..-......
0x0020: 0001 96aa 1f90 bc64 acfd 0088 4ae2 8018 .......d....J...
0x0030: 0866 feee 0000 0101 080a 0016 31db 0016 .f..........1...
0x0040: 31da 1603 0100 8610 0000 8200 80ae d0f6 1...............
0x0050: bb61 7295 d39c 5af5 8bbe 70b5 d42c 7e37 .ar...Z...p..,~7
0x0060: 5678 d1be 9641 f6b0 0dc5 d88b 599d d262 Vx...A......Y..b
0x0070: f0e6 39f0 a1a4 42c0 89af 50fb 4998 0685 ..9...B...P.I...
0x0080: f3db d028 6ab3 aa80 308a d592 debb 75ef ...(j...0.....u.
0x0090: 2097 017c 6205 3790 6ce6 c26b 4d1c 6ef7 ...|b.7.l..kM.n.
0x00a0: 743e 3f94 2b75 aa67 4ff1 4330 9319 5960 t>?.+u.gO.C0..Y`
0x00b0: 4087 5370 b8aa 5b67 5279 bf0a 8979 1a54 @.Sp..[gRy...y.T
0x00c0: 2b92 37cf 199a a944 8ea0 0719 8f14 0301 +.7....D........
0x00d0: 0001 0116 0301 0030 ffc7 337a b18b 7d92 .......0..3z..}.
0x00e0: 6a9c 42ae cd5d 9afe 8104 c5f4 0181 c2d6 j.B..]..........
0x00f0: 40ed 7c12 229b d34d 77e7 0dc5 6385 e486 @.|."..Mw...c...
0x0100: 0a9b a10b d85c 03f2 .....\..
[...]
As you can see, there is no clear text so it works! Maybe this solution is a bit intrusive but... it is quick, easy and lightweight. I don't know if there is a better solution but I would really like to know.
Fri, 22 Nov 2019 00:45